文档理解(Document Understanding)是计算机视觉和自然语言处理的交叉研究领域,在当前数据驱动的时代下,让计算机代替人工自动从最为常见的非结构化商业文件中准确地提取出所需内容以及内容间的关系逐渐变得可行。
壹沓科技的NLP专家在20年前投身行业之初就已经认识到统计机器学习在文本内容处理方面的强大能力——当时,SVM算法对报刊内容主题分类任务在数万篇历史内容的训练下可以达到98%以上的准确率,而分类任务又可以认为是一切NLP任务中的最小算法单元。进入互联网的时代,海量文本数据和算法的结合可以说为机器智能在特定任务中达到乃至超越人类水平投来了一束希望之光。
壹沓团队自2016年就开始以搜索引擎技术每天从互联网上获得TB级别的文本素材,通过大文本挖掘技术的研发过程,对非结构化数据的清洗、识别、抽取、分析积累了大量的经验。面向文档智能的NLP任务,我们在原有技术基础上,成功研发了面向多个领域的复杂表单关键字段抽取,PDF非可视部分抽取,低质文档OCR增强等智能化算法。解决方案型的通用文档理解技术,我们也已经提上研究日程。
壹沓科技预言,愿意率先拥抱相关智能技术的企业,其业务运营效率的提升将在未来几年内成倍体现。我们的AI团队利用海量行业文档数据开展相关课题的研究表明,在通用表格键名抽取,键值配对,OCR识别纠错等方面无监督学习可以高度自动化地完成领域适应性建模,相信不久之后就能在真实落地业务中帮助客户快速提升企业竞争力。
在目前办公和企业运营领域,需要处理的文档可能是电子格式文件,也可能是扫描件,一些常见的商业文件,例如发票,税单,订单,财务报告等等。文档内容抽取对文档的逻辑和语义分析,并抽取人可以理解的信息转换成机器可读的格式。抽取的信息不仅仅是时间,姓名或者身份证号这些文本层面的内容,还有文本间的逻辑结构。目前的传统信息抽取技术可以处理自然语言中的信息,但是非结构化文档同时包含文本和排版的信息,文本被分成了块,段,表等等。非结构化表格的提取难点在于,版面结构和语义关系的结合。非结构化表格虽然都是文字,但是用传统的关系抽取方法是不可行的,因为表格内容很多是短语、单词而不是一句话。
目前国际前沿的研究工作都已经开始着手如何将语义信息和结构信息结合,大量开展计算机视觉和知识表征技术联合学习来提升计算机对于文档结构的理解准确率,按照目前的趋势,该项技术将很有可能如人脸识别等AI应用一样在短期内成熟,开始大规模进入商用领域。
文档理解技术前传
l 结构化——文档理解的初心
在上世纪九十年代,文档理解的概念逐渐流行起来,当时研究对象是杂志或者刊物上的文章排版(如下图所示)。研究内容聚焦在文档的分块以及块与块之间的逻辑架构层。虽然当时的研究方向不是现在的主流方向,但是这个时期论文提出了很重要的两点:文档分析是从文档中提取出几何关系;文档理解是把几何关系映射到逻辑结构。这也是之后文档内容抽取工作的主要思路。

l 面向商用——聚焦表单理解
在21世纪初,研究方向开始投向更复杂的文档(如下图),开始偏向于考虑真实的商业应用。在Making Documents Work: Challenges for Document Understanding里,作者Dengel详细地阐述了当时流行的研究方法——主要是基于特征学习。对于表格的结构抽取,大多数论文是定义了一些模板来指导表格分析过程,但这样的缺点是不能通用地适应海量表格。对于没有明显表格结构的表单,只依赖于文本坐标自下而上的块聚类,完全忽略了表格中的行列概念,甚至列元素不需要对齐。对于表格的内容理解,多数方法引入了外部知识,对于特定领域的字段会有固定知识库。为了提取所有的相关信息,知识的引入起到十分重要的作用,尤其是当一些字段不常用且有特殊意义时。

l 曙光初露——统计学习方法
在2010年左右,随着统计学习的流行,文档理解也引入了概率方法。在A probabilistic approach to printed document understanding一文中,作者Bartoli依然是从文本和坐标两个角度入手,但是是用统计的方法计算板块之前的相关性。如下图所示,作者通过比较坐标,文本框大小,距离百分比等等来精细化文档抽取。但是由于数据集的局限性,作者的测试数据集只有800多份。仅是基于统计学习在小样本上学习还无法支撑更多类型的样本。
大数据+深度学习=大突破
虽然文档理解领域已经研究了二十多年,但是因为准确度不够高以及商业落地迟迟未能展现,而伴随大型数据集的发布,深度学习技术开始发力,最近几年,该领域连续取得了突破性的进展。2015年,卡耐基梅隆大学发布了数据集RVL_CDIP,它包含16种类型文档,每种类型25000张图片,它可以用于研究某一固定领域或者是文档分类。

2019年,洛桑联邦理工学院信号处理实验室发布了数据集FUNSD,它包含199篇包含大量噪声的扫描件文档(如下图)。

并标注了其中的文本块,语义实体和实体关系,下图是一个文本分区的样本。

随着深度学习的广泛应用,神经网络也被应用于文档理解。尤其是BERT提出后,在多项文本理解的任务中,横扫NLP传统方法,这为文档智能研究者通过语义表征和预训练方法的尝试带来了重大启示。
l 预训练模型横空出世
2020年六月微软发布了模型LayoutLM,针对文档理解的文本和版面预训练模型,如下图所示,论文的研究对象面向所有格式的文档。作者Yiheng Xu和Minghao Li使用其OCR或者PDF解析以及Faster R-CNN得到的图像embeddings来做预训练。

同年七月,微软发布了TableBank数据集,包含了一共417234个被标注过的高质量表格,涉及多个领域,专门用于研究表格定位和表格识别,里面包含了大量的复杂表格(如下图所示)

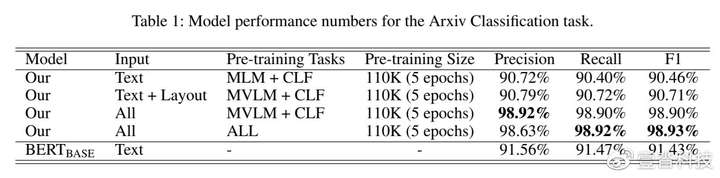
同年九月IBM Research也发布了一个预训练框架:Towards a Multi-model, Multi-task Learning based Pre-training Framework for Document Representation Learning,作者Pramanik测试了文本分类,信息抽取,文档抽取三个下游任务(如图所示)。这篇文章改善了LayoutLM中没有把图片信息和文本信息一起训练,只是把图片信息和文本信息相加的问题。值得一提的是,与LayoutLM一百多万的预训练数据集相比,IBM Research只用了11000个预训练数据,而LayoutLM的性能只比IBM Research高了1%,这篇文章证明了在相对较小样本数据集上的预训练也可以达到很好的效果。

同时该模型还在另一项文档分类任务中大幅超越了单纯基于内容结果BERT分类模型,达到惊人的98.93%
l 针对具体应用场景的表示学习研究

去年七月份Google Research发表了Representation Learning for Information Extraction
From Form-Like Documents。与上面两篇论文不同的是,作者Majumder并没有使用图像信息嵌入,而是只用OCR结果中自带的文本坐标来进行排版的编码。这篇论文旨在针对某一特定领域的表单,通过少量人工标注样本的学习,去抽取更多其他格式未曾见到过的文档。这篇文章结合了先验知识,基本常识以及神经网络架构来学习每一个文本块的表征。文章中提出了三个对于表单的基本认知:每一个字段往往匹配一个显而易见的类别,例如invoice_date只会匹配日期,不会匹配到金额;字段之间有明显的视觉关系,当一个表中有多个日期时,我们很轻松地可以辨别它们分别属于哪个字段;大多数key word都来自一个特定领域的小型词表。基于这三点认知,文章结合语义关系和位置关系对每个字段的候选项进行打分来匹配键值对。
这篇论文的发现在于结合了之前的研究方法提出了一个可以解决实际商业问题的模型,但它的局限性也很明显,只研究了发票和收据两个领域,尽管实验结果分数很高,但是实验本身提取的字段较少,支票提取了七个字段,收据只提取了两个字段,并且提取的都是日期,金额,单号这样特征明显且都是单行的文本。此外,尽管论文的目的是从小样本中学习,但实验用到了一万多份人工标注样本,前期的数据准备也有不小的投入。
l 图神经网络的尝试
除了预训练框架学习文档表征之外,图神经网络也被应用于学习文本和图像的联合表征。去年ICPR会议论文Named Entity Recognition and Relation Extraction with Graph Neural Networks in Semi Structured Documents一文中作者Carbonell根据文档的版面特性,把一个个文本框当作一个节点,节点之间的线如果标为1则表示两个节点有关系,生成的图送入GNN中训练,因此关系抽取问题变成了一个节点二分类问题。
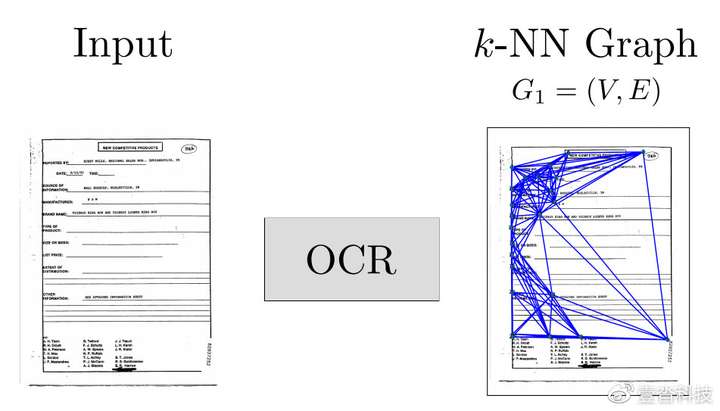

作者除了研究现代文档,还尝试使用相同的手段针对古代手写文档(如上图文件3)进行信息抽取,希望在将来能够对专业历史研究者提供文献分析的机器智能的帮助。
2021文档智能落地进行时
文档智能的研究从版面分析,结构统计,深度学习一路走来。尽管通用文档理解乃至文档智能处理仍是一个十分有挑战的任务,但我们十分高兴地看到一年来微软和IBM等企业研究团队都推出了具有突破性意义的预训练网络模型,将相关研究的进程得以加速推进。
然而壹沓的AI团队也深深意识到,这些成果与能够广泛运用于企业实际场景的软件还有很大的距离,但也正因如此,我们的算法工程师和业务专家满怀激情,勇于挑战IT行业巨头,正通过扎实而深入的工作,在这个领域取得进步并超越竞争对手。在未来几个月内,壹沓科技将为我们服务的客户提供基于深度学习与知识图谱技术融合的文档智能解决方案。
2021 —— 壹沓文档智能,由您见证


