2020年突发的新冠疫情虽然对我国实体经济产生了巨大影响,但由此刺激线上经济快速发展,在很大程度上对冲了消极影响。根据2021年1月国家统计局的最新数据——2020年,我国实物商品网上零售额97590亿元,增长14.8%,对比城镇消费品零售总额比上年下降4.0%,无疑进一步揭示了电商流通加速替代传统零售的大趋势。
后疫情时代,无论时新潮牌还是传统品牌都在加码电商渠道的投入,伴随线上销售的占比节节攀高,面向电商平台的精细化运营管理必然越来越重视消费者产生的海量评价意见数据。通过大数据技术,对多个平台的商品品类或SKU采集这些评论数据在今天已经不是一件难事,然而要精准、快速地理解消费者意见的内含,真正驱动销售运营或产品创新目前市场上还鲜有能够满足普遍需求的AI产品和服务。
壹沓科技的AI团队在多年以来积累的面向传播的篇章级情感分析技术的基础上,研究自然语言处理(NLP)技术最新成果和行业实践经验,正在研发接近无监督模式的细粒度通用情感分析引擎。下文将为读者揭示细粒度情感分析这一技术的前世今生,并分享壹沓科技在该任务方向上的经验认知——
在自然语言处理(Natural Language Processing,NLP)领域,文本情感分析,也被称为观点挖掘(Opinion Mining),是对实体(包括产品、服务、组织、个人、议题、事件、话题及他们的属性等)表达的观点、评价、态度和情感进行计算的专项任务。伴随互联网和电子商务的诞生,自2000年以来,情感分析逐渐发展成为的一个基础研究和产业实践都非常重视的技术方向。
近年来,以海量训练数据作为基础,对于评论语料的整体情感分析已经达到了可实际商用的精度,行业对该技术提出进一步深入发展的需求,研究热点已经逐步聚焦到方面级别的细粒度情感分析(Aspect Based Sentiment Analysis - ABSA),国际语义评测大会SemEval从2014年起连续三年将ABSA任务作为其子任务,梳理了四项任务,提供了一系列人工标注的基准数据集。最近,基于深度学习技术的方面级情感分析研究蓬勃兴起,取得了突破性进展。
什么是细粒度情感分析和观点挖掘?
- 评论整体情感分析不同细粒度情感分析和意见挖掘更注重于属性词和情感词的识别和抽取,对评论中的多个实体或属性分别计算情感倾向,从而获得多维度情感信息量,进而获得更有效的信息,充分展现了评论文本数据的应用价值。比如给定一句产品评论,我们需要能够从中确定哪些词是用户所评价的产品属性,哪些词是用户的态度。
- 例如,在评论“XX 手机真的很不错,但是就是屏幕有点差”中,“手机”和“屏幕”都是用户所评价的产品属性,即“评价对象”;而“不错”和“差”则都是用户的态度,即“评价词语”。我们需要做的是提取出这几个词语,并确定词语之间的搭配关系。
细粒度情感分析技术更具面向运营的商业价值
- 就电商而言,目前主流的电商平台在处理商品评论的情感分类时,仅直接将商品评论整体分为好评、差评、中评,然而用户在针对一件商品发表评论时,除了会给出总体评价,通常会针对该实体的属性进行评价。比如“这家餐厅的口味很不错,就是服务态度太差了”,针对口味这个评价对象给出了好评,针对服务这个评价对象却给出了差评。类似主流的分类方法如图所示,针对手机质量本身给出了好评,却对服务态度给出了差评。而该平台仅将整条评论语句情感倾向性归为中评类。通过这两个实例会发现如果仅对整体语句进行情感分类不仅会导致该条评论信息的重点缺失,还会导致情感分类结果的准确度下降,如果采用细粒度情感分析和意见挖掘这项技术方法对商品评论信息进行细粒度的情感划分即按照不同情感对象进行情感分类,就能为品牌电商运营方提供更多维度的有效信息,通过在线数据分析OLTP可以针对不同品类、不同商品、不同渠道、不同营销活动分别建立洞察,甚至可以对比竞品的消费者动向,即时根据市场反馈调整运营重点和产品迭代。
(上例:消费者对产品基本满意,但对代言人广告不满)
同时,细粒度情感分析是也能够加强品牌方和消费者的连接。电商商品的褒贬口碑往往决定了其销售的命运,通过对产品评论的细粒度情感分析可以深入地了解用户对产品的反馈,实现企业对产品设计的改进。若能快速定位用户评价中所说的问题,并且快速进入运营处理流程,会带来消费者对企业服务质量有显著的体验提升。
具体来说,就是可以将原始评论信息进行NLP分析处理之后,由AI技术抽取观点、分类聚合,给出具备明确情感倾向(好、中、差)的评价数据,再由企业管理部门分配给售后、物流、服务报表等环节,进行服务人员的评分考核、产品改进。
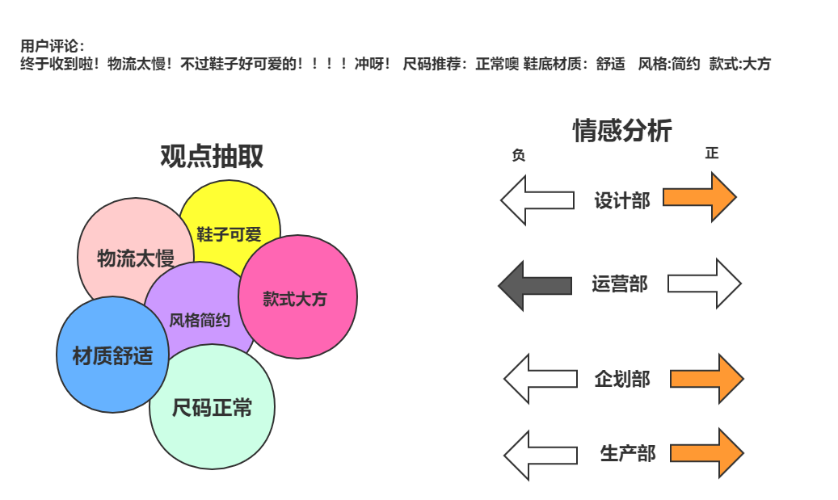
电商评论的细粒度情感分析技术行业现状
目前,可实用的评论情感分析大都集中在粗粒度层面上,即只能进行对单条平论整体的情感分类,如正向和负向等等。而且对于粗粒度层次的情感分析的研究也停留在篇章级以及句子级的层面上,这就导致了其不能从更加细致的层面上分析出事物主体的各个属性以及特征之间的关系,或者说是情感极性。显然,粗粒度情感分析层面的研究已经不能满足人们的需要,社会大众以及商家、生产商需要从更细致的层面上了解产品以及其他事物主体,这就要求我们从更加细致层面上对事物主体进行分析,使用户更加直观的获取所需的信息,减少信息获取量。
现在各大云平台都有推出了自然语言处理相关项目的服务。如阿里云的自然语言处理、腾讯云的自然语言处理NLP,还有百度AI开放平台的自然语言处理模块。这三个平台都有提供情感倾向分析模块,但细粒度只是停留在句子级的层面上。此外,百度AI还提供了评论观点抽取模块,但只抽取到适应预训练过的几个行业场景的少数一些分类维度。在面向实际的电商运营,大平台的标准化服务都显得挖掘深度不足,实用性欠佳。
壹沓科技在实际业务中遇到的对某品牌鞋的评价,“显得脚大,但是舒服”,在该评价实例中,针对鞋子的外观这个评价对象该买家给出了差评,而针对鞋的舒适度这个评价对象则给出了好评。而腾讯云和百度AI平台都将整条评论语句情感倾向性归为好评类。在用户表达的多评价对象情感有矛盾的案例中,原有情感分析技术往往不能获得准确的结果。
壹沓AI细粒度情感分析框架
对评论文本进行数据清洗,提取主题词和情感词。首先,用户的在线评论文本通常包含与情感分析无关的噪声数据,因此,可以使用正则表达式去除表情、占位符等特殊符号,再借用停用词词表去除停用词。其次,由于句子的表示方式灵活且复用率低,因此现有的自然语言处理任务通常需要对句子进行分词,将词视为最小的可以独立运用的单元。最后,要将文本转化为便于存储和处理的结构化格式。这一目标主要采用向量空间模型来构建文本向量。
对用户评论的中的主题词和情感词提取之后,还需要抽取出主题词和情感词之间的评价配对关系。利用前面模块处理好的数据集训练模型、并用模型来对文本进行情感分类。最后将各个时刻的前向隐藏状态与其对应时刻的反向隐藏状态相结合,得到该时刻的最终输出。下图为细粒度情感分析流程框图。
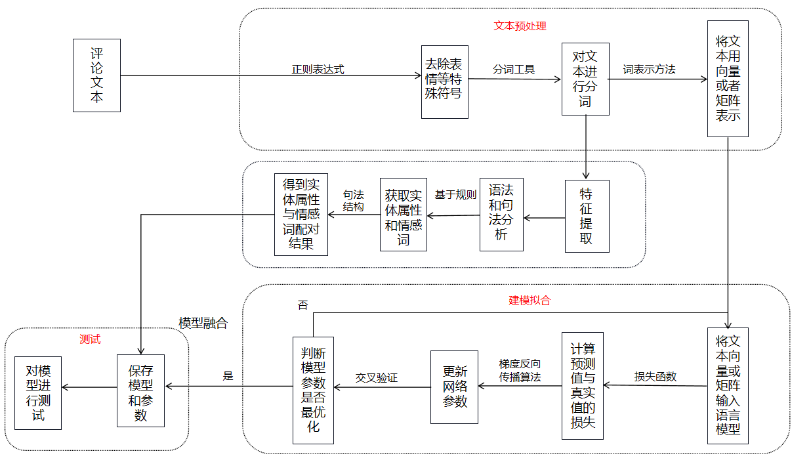
细粒度情感分析流程框图
细粒度情感分析及意见挖掘的相关技术
壹沓科技AI部门在细粒度情感分析及意见挖掘方面也取得了部分进展,下面介绍几个对于该项任务中几个比较关键得技术方法,希望通过本文能够给喜欢和热爱NLP的伙伴们带来一些收获。
主题词和情感词之间的评价配对关系
在自然语言处理任务中可以将主题词和情感词之间的评价配对关系当成关系分类任务来解决。可以将任务简化为对抽取的主题词和情感词进行逐对判断其是否为配对关系即可。例如“这款手机的外型很好看,但是电池真的是不耐用”一句中,(外型,好看)与(电池,不耐用)是正确的配对,但(外型,不耐用)不是正确的配对关系。如下图所示。

目前,基于传统的机器学习的语言模型已经能有效地处理这类任务,但往往对语法不规范的电商评论准确性下降不少。通过深度学习的方法在海量语料中进行训练,利用改进的LSTM神经网络—AF-LSTM对比可以取得不错的效果。
该模型的优点在于让注意力层专注于学习上下文词的相对重要性,不用学习aspect和单词之间的关系。降低了计算复杂性和存在过拟合风险。如下图所示。在输入经过 embedding 层和 LSTM 层之后进入到 Word-Aspect Fusion Attention Layer,这也是该模型的重点。如图所示:
「Normalization Layer(optional):」 在隐状态矩阵和 aspect vector 进行交互之前可以选择性地对其进行正规化操作,可以选用 Batch Normalization;
「Associative Memory Operators:」 用于计算 context word 和 aspect word 之间的关系。有两种:circular correlation 和 circular convolution;
「Learning Attentive Representations:」 将 aspect 和 context 进行 fusion 之后得到的向量表示进行 attention 操作。
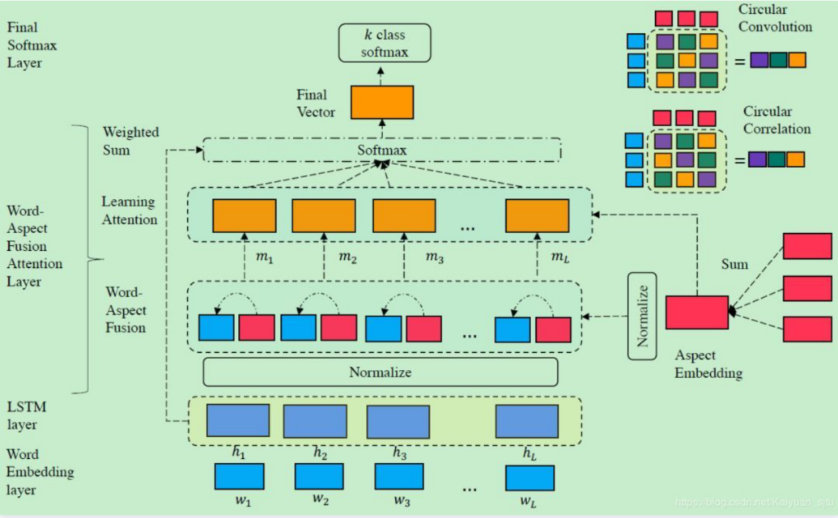
AF-LSTM模型整体框架
文本情感极性判断
对评论进行完主题词和情感词的配对提取之后,需要对本句评论的情感极性做出判断,方便用户和商家更好的了解顾客对商品的情感倾向。通过大量观察实验中的评论数据,发现有很多用户评论中所表达的包含若干个主题,用户对于不同的主题所表达的情感极性也是不一样。下表列举了用户评论中所表达的包含若干个主题的评论。

用户评论多主题词情感极性标注样例
对于表用户的评论“手机的外壳看起开很舒服,触屏键特别敏感,就是待机时间不长。”这条评论中,一共存在的主题词和情感词对有(外壳,舒服)、(触屏键,敏感)、(耗电,快)。该评论中对于不同的主题词有着不同的情感极性。如果整体对该评论打上情感极性标签,是无法分到积极、消极和中性的类别中,但是分别对于每个主题词,可以很准确地判断其对应的情感极性。因此,如果能对每个含有主题词的短句进行情感极性判断的效果是比直接对整句评论进行情感极性判断的更要准确。下面给大家介绍一种融合词性注意力机制的细粒度情感极性分析模型BiLSTM-Attention+POS+Multi-Dic。
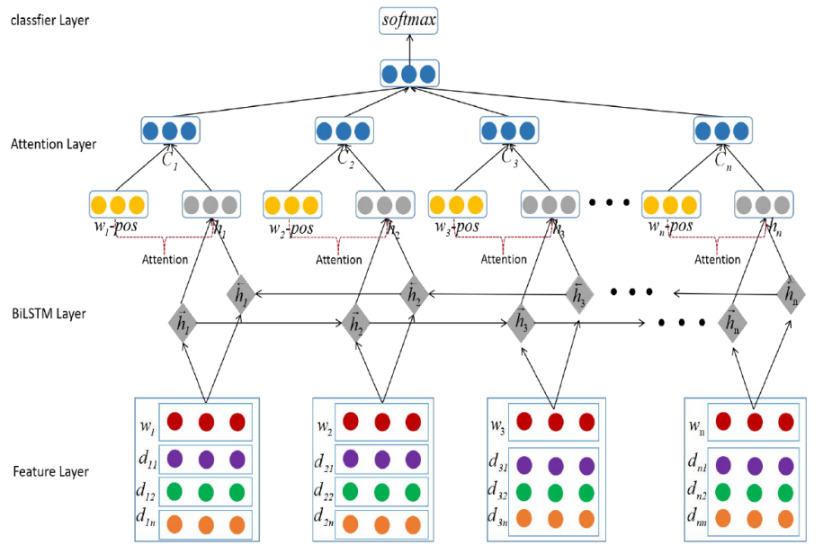
融合词性注意力机制的细粒度情感极性分析模型
首先将评论语句中的各单词及对应的词性和多领域词典特征进行向量化编码,分别转换成固定长度的低维稠密向量表示。然后对单词向量及对应的多领域词典向量进行拼接输入到下一层中进行特征学习。特征学习主要利用 Bi-LSTM 网络模型的优势提取文本的高维抽象特征,然后结合注意力机制将待抽取实体的语句中各单词及其多领域词典特征的高维抽象特征取出,与各词单元对应的词性特征向量进行注意力关注计算,从而得到词性特征对预测目标的贡献矩阵。把注意力层的输出特征进行拼接,即得到最终得到的文本特征表示 Ls。
如上图所示, 在BiLSTM 的基础上提出 BiLSTM-Attention+POS+Multi-Dic 分类模型,模型构建多领域词典特征,融合 Attention 机制,适当分配词性的注意力对文本情感极性分类的权重贡献度,对文本情感极性分类的有着很大的提高。
展望未来:
壹沓科技AI团队在面向电商商品评论的细粒度情感分析问题上取得了一些阶段性成果,但是,为了能够更好地完成通用的分析引擎,还有很多内容值得进一步深入研究与改进优化。下一步的工作将会围绕着以下几个方面展开:
- 基于大规模的预训练网络进行完全端对端成对抽取评论中的主题词和情感词在某些数据集上有很好的测评效果,后续的工作可以尝试使用联合解码的方式,同时识别句子中的主题词和对应的情感词。
- 虽然我们的方法已经考虑到了隐含实体,基本解决了评价中没有显式评价对象的问题,但是很多用户的评价往往还缺乏连续的显式评价词(通过短语整体体现情感倾向),如何高效地识别这些隐式情感并准确分类也有待下一步解决。
- 面向实际商用和客户观感,如何有效评价结果中的对象词和情感词的抽取置信度往往会决定最终上线产品的客户满意度,这方面的工作也待后续开展。


